- Published on
Rust入门笔记(十)
- Authors

- Name
- Et cetera
- Q: 在 Rust 下,分配在堆上的数据结构可以引用栈上的数据么?为什么?
- Q: main()函数传递给 find_pos() 函数的另一个参数 v,为什么没有被 move 所有权
- 另外 Clone trait 是 Copy trait 的超集,实现后通过调用.clone()方法可以实现深拷贝
- 另一点 Copy trait 和 Drop trait 不能共存
- Q: 为什么可变引用没有实现 Copy trait
- 使下面代码运行
- Rust 中的运行时动态检查和编译时静态检查
- Rc(对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者)
- Box::leak() 机制
- 实现 DAG(Directed Acyclic Graph)
- RefCell
- 内部可变性(interior mutability)
- 实现可修改 DAG
- Arc 和 Mutex/RwLock
- 练习
- 写一段代码,在 main() 函数里生成一个字符串,然后通过 std::thread::spawn 创建一个线程,让 main() 函数所在的主线程和新的线程共享这个字符串
- 深入思考:Rc 的 clone():传入的参数是 &self ,是个不可变引用,为什么会增加引用计数呢?(或者说为什么这里对 self 的不可变引用可以改变 self 的内部数据呢?)
- 总结
Q: 在 Rust 下,分配在堆上的数据结构可以引用栈上的数据么?为什么?
A: 可以,因为 Rust 的所有权系统会在编译时检查引用的有效性,所以不会出现悬垂指针的情况
Q: main()函数传递给 find_pos() 函数的另一个参数 v,为什么没有被 move 所有权
A: 因为 u32 实现了 Copy trait,所以在传递给 find_pos() 函数时,会在内存上按位复制一份(浅拷贝),而不是 move
fn main() {
let data = vec![10, 42, 9, 8];
let v = 42;
if let Some(pos) = find_pos(data, v) {
println!("Found {} at {}", v, pos);
}
}
fn find_pos(data: Vec<u32>, v: u32) -> Option<usize> {
for (pos, item) in data.iter().enumerate() {
if *item == v {
return Some(pos);
}
}
None
}
简单总结:
- 原生类型,包括函数、不可变引用和裸指针实现了
Copy - 数组和元组,如果其内部的数据结构实现了
Copy,那么它们也实现了Copy - 可变引用没有实现
Copy - 非固定大小的数据结构,没有实现
Copy
另外 Clone trait 是 Copy trait 的超集,实现后通过调用.clone()方法可以实现深拷贝
// 简单实现
#[derive(Debug, Clone)]
struct CustomType {}
// 复杂实现
impl Copy for CustomType {}
impl Clone for CustomType {
fn clone(&self) -> Self {
todo!()
}
}
另一点 Copy trait 和 Drop trait 不能共存
在 Rust 中,当一个类型实现了 Copy trait 时,它的值会在需要复制时进行位拷贝,而在离开作用域时不会调用 Drop 实现.这是因为位拷贝只是简单地复制原始值的位,而不涉及到资源的释放或其他清理操作.相反,当一个类型实现了 Drop trait 时,编译器会生成一个 Drop 实现,在值离开作用域时,会自动调用 Drop 实现执行清理操作.
由于 Copy trait 和 Drop trait 的行为和语义不同,它们不能同时存在于同一个类型上.因为如果一个类型实现了 Drop trait,编译器会自动生成对资源的清理操作,而实现了 Copy trait 的行为却是进行简单的位拷贝,这样会引起潜在的问题,例如多次释放同一个资源.
Q: 为什么可变引用没有实现 Copy trait
A: 因为可变引用的值是可变的,如果实现了
Copy trait,那么在进行位拷贝时,会导致多个可变引用同时指向同一个值,这样就会违反 Rust 的可变引用规则,即同一时刻只能有一个可变引用指向某个值
使下面代码运行
fn main() {
let mut arr = vec![1, 2, 3];
// cache the last item
let last = arr.last();
arr.push(4);
// consume previously stored last item
println!("last: {:?}", last);
}
原因是 last() 方法返回的是一个不可变引用,而 push() 可能会使 Vec 扩容(重新分配 Vec 的内部缓冲区),导致之前的引用失效,所以编译器会报错
// 成功运行,两种思路
// 先使用后 consume arr
// fn main() {
// let mut arr = vec![1, 2, 3];
// // cache the last item
// let last = arr.last();
// // consume previously stored last item
// println!("last: {:?}", last);
// arr.push(4);
// }
// 另一种方式
// 对 arr 进行 clone,consume 不影响 clone 的值
fn main() {
let mut arr = vec![1, 2, 3];
// cache the last item
let last = arr.last().cloned();
arr.push(4);
// consume previously stored last item
println!("last: {:?}", last);
}
Q: 那为什么
Vec的push()方法会导致之前的引用失效 A: 因为push()方法可能会导致Vec的内部缓冲区重新分配,这样之前的引用就会失效
Q:内部缓冲区是什么? A:
Vec内部的数据结构是一个指向堆上分配的缓冲区的指针,这个缓冲区的大小是可变的,当Vec的元素个数超过缓冲区的大小时,Vec会重新分配一个更大的缓冲区,并将原来的元素复制到新的缓冲区中,然后释放原来的缓冲区.
Rust 中的运行时动态检查和编译时静态检查
Rust 通过使用使用引用计数的智能指针:Rc(Reference counter) 和 Arc(Atomic reference counter) 实现运行时动态检查
Rc(对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者)
Rc 会把对应的数据结构创建在堆(heap)上,并在堆上记录引用计数,当引用计数为 0 时,释放堆上的数据结构(Ps:堆是唯一可以让动态创建的数据被到处使用的内存区域)
use std::rc::Rc;
fn main() {
let a = Rc::new(1);
}
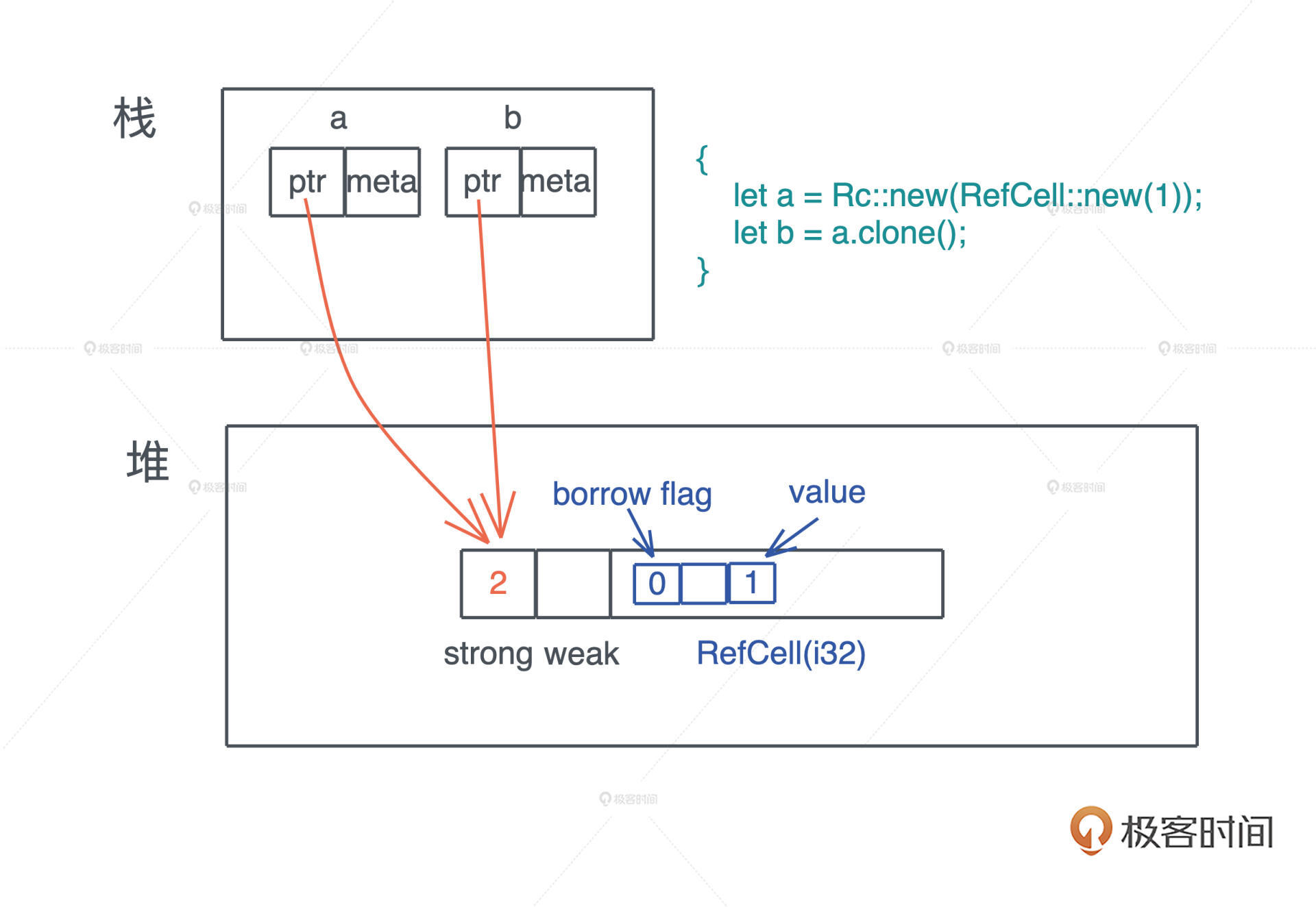
之后,如果想对数据创建更多的所有者,可以通过 clone() 来完成
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数.而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存
下列代码创建了三个 Rc,分别是 a、b 和 c.它们共同指向堆上相同的数据,也就是说,堆上的数据有了三个共享的所有者.在这段代码结束时,c 先 drop,引用计数变成 2,然后 b drop、a drop,引用计数归零,堆上内存被释放.
use std::rc::Rc;
fn main() {
let a = Rc::new(1);
let b = a.clone();
let c = a.clone();
}
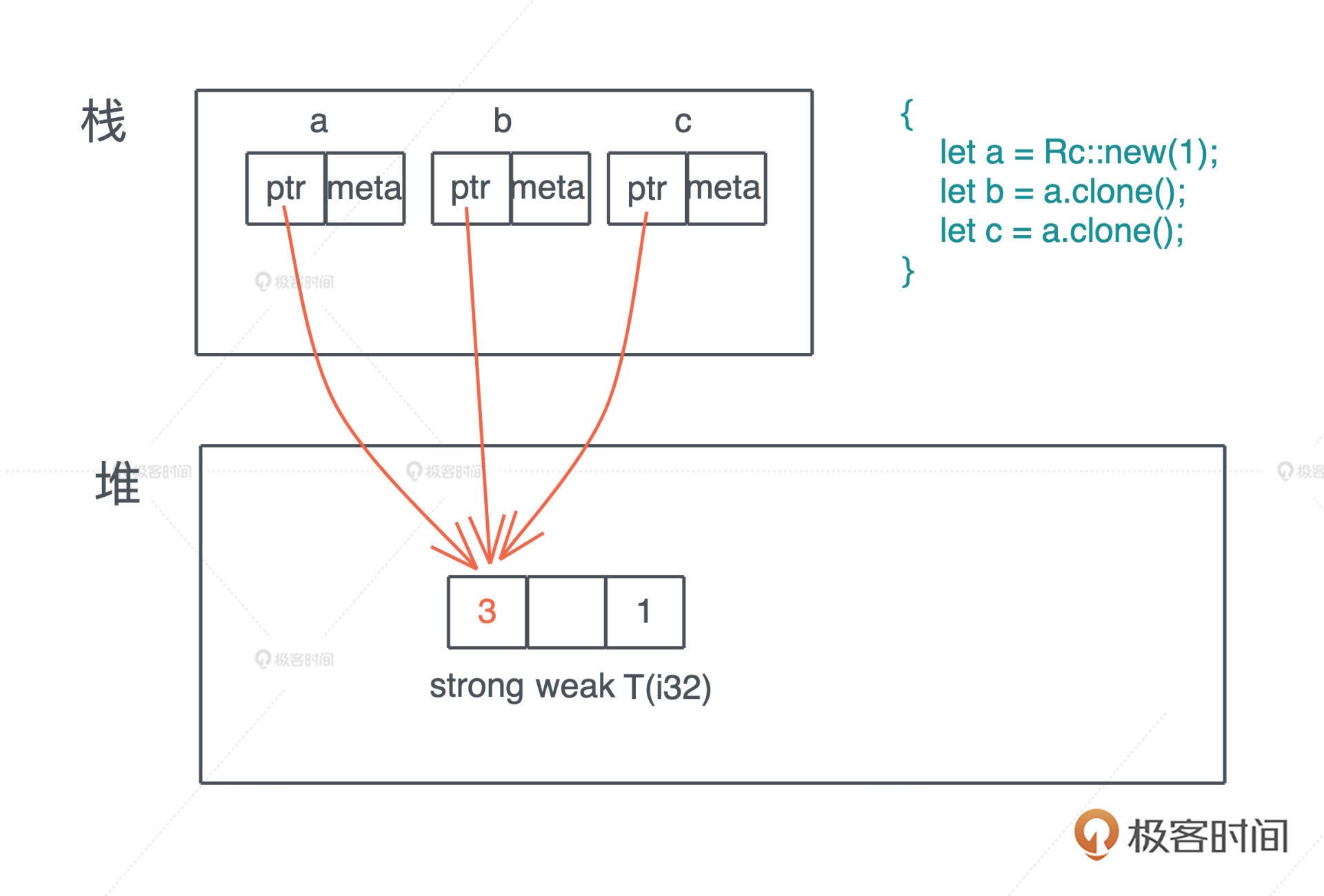
Q: 为什么上面代码生成了对同一块内存的多个所有者,但是,编译器不抱怨所有权冲突呢? A: 因为 Rc 实现了 Copy trait,所以在进行位拷贝时,会在堆上创建一份新的引用计数,而不是 move
// 源码中 Rc clone 方法的实现
fn clone(&self) -> Rc<T> {
unsafe {
// 增加引用计数
self.inner().inc_strong();
// 通过 self.ptr 生成一个新的 Rc 结构
Self::from_inner(self.ptr)
}
}
通过源码实现总结,首先 a 是 Rc::new(1) 的所有者;然后 b 和 c 都调用了 a.clone(),分别得到了一个新的 Rc,所以从编译器的角度,abc 都各自拥有一个 Rc
Box::leak() 机制
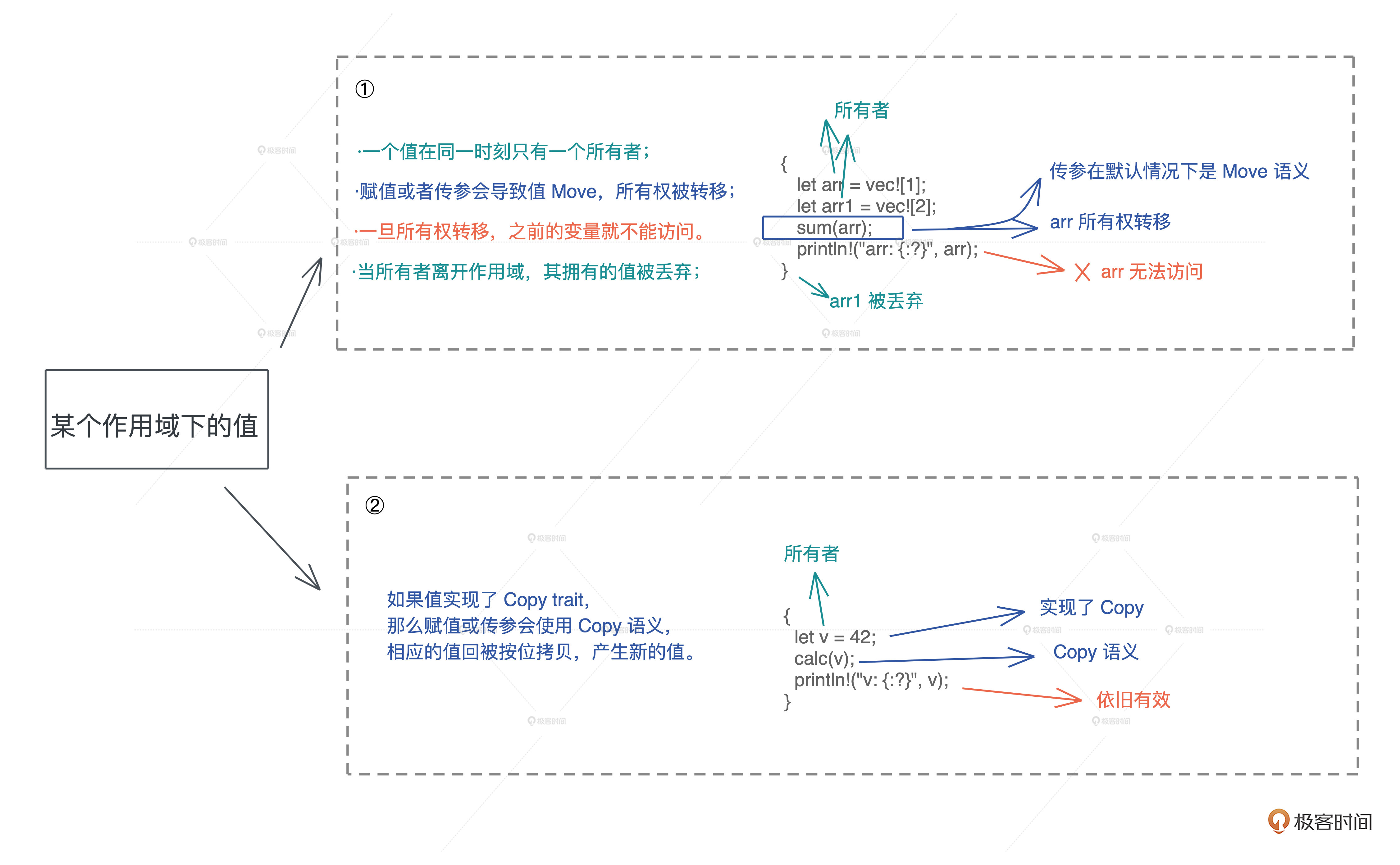
单一所有权模型:
- 变量绑定拥有对值的所有权:当你将一个值绑定给变量时,该变量成为该值的唯一所有者.
- 所有权的移动(Move):将所有权从一个变量转移到另一个变量,原始变量将无法再访问该值.这样可以防止两个变量同时修改同一个值,从而提供了内存安全性.
- 借用(Borrowing):通过借用(引用
&)来临时共享值的访问权限,但并不转移所有权.借用有可变借用和不可变借用两种形式,有严格的生命周期限制. - 生命周期(Lifetime):所有权和借用都受到生命周期的限制,确保了引用的有效性和内存安全性.
Drop trait和析构函数:当所有权超出范围时,Drop trait定义的析构函数自动调用释放资源,避免了资源泄漏.
在所有权模型下,堆内存的生命周期,和创建它的栈内存的生命周期保持一致.所以 Rc 的实现似乎与此格格不入. 如果完全按照单一所有权模型,Rust 是无法处理 Rc 这样的引用计数的.
Rust 必须提供一种机制,让代码可以像 C/C++ 那样,创建不受栈内存控制的堆内存,从而绕过编译时的所有权规则.Rust 提供的方式是 Box::leak()
Box 是 Rust 下的智能指针,它可以强制把任何数据结构创建在堆上,然后在栈上放一个指针指向这个数据结构,但此时堆内存的生命周期仍然是受控的,跟栈上的指针一致.这样就可以绕过编译时的所有权规则,创建出不受栈内存控制的堆内存.
Box::leak(),顾名思义,它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象
所以我们相当于主动撕开了一个口子,允许内存泄漏
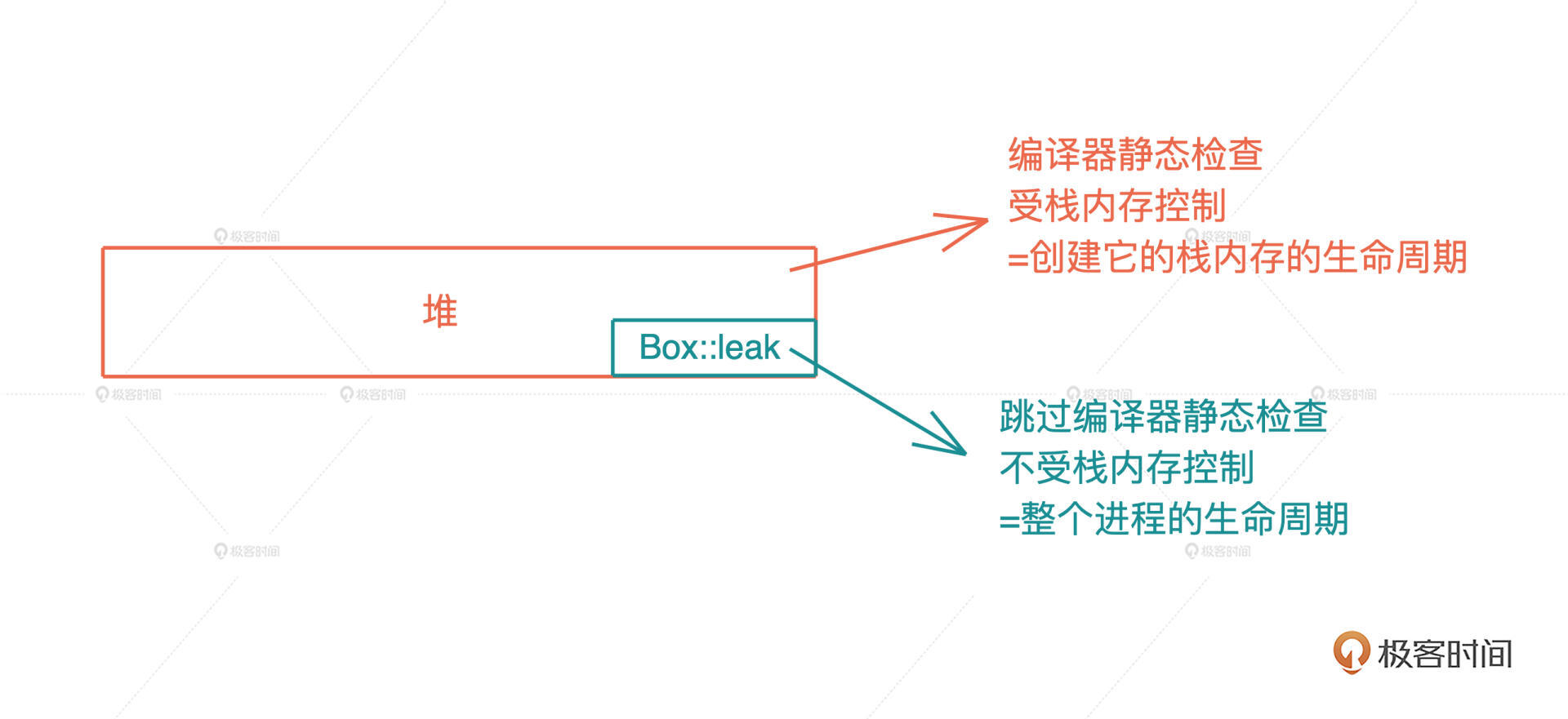
注意,在 C/C++ 下,其实你通过 malloc 分配的每一片堆内存,都类似 Rust 下的 Box::leak().它符合最小权限原则(Principle of least privilege),最大程度帮助开发者撰写安全的代码
有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查,保证 Rc 指向的堆内存,有最大的生命周期,然后我们再通过引用计数,在合适的时机,结束这段内存的生命周期.如果你对此感兴趣,可以看 Rc::new() 的源码
#[cfg(not(no_global_oom_handling))]
#[stable(feature = "rust1", since = "1.0.0")]
pub fn new(value: T) -> Rc<T> {
// There is an implicit weak pointer owned by all the strong
// pointers, which ensures that the weak destructor never frees
// the allocation while the strong destructor is running, even
// if the weak pointer is stored inside the strong one.
unsafe {
Self::from_inner(
Box::leak(Box::new(RcBox { strong: Cell::new(1), weak: Cell::new(1), value }))
.into(),
)
}
}
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
静态检查,靠编译器保证代码符合所有权规则;动态检查,通过Box::leak()让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放
实现 DAG(Directed Acyclic Graph)
假设 Node 就只包含 id 和指向 下游(downstream) 的指针,因为 DAG 中的一个节点可能被多个其它节点指向,所以我们使用 Rc<Node> 来表述它;一个节点可能没有下游节点,所以我们用 Option<Rc<Node>> 来表述它
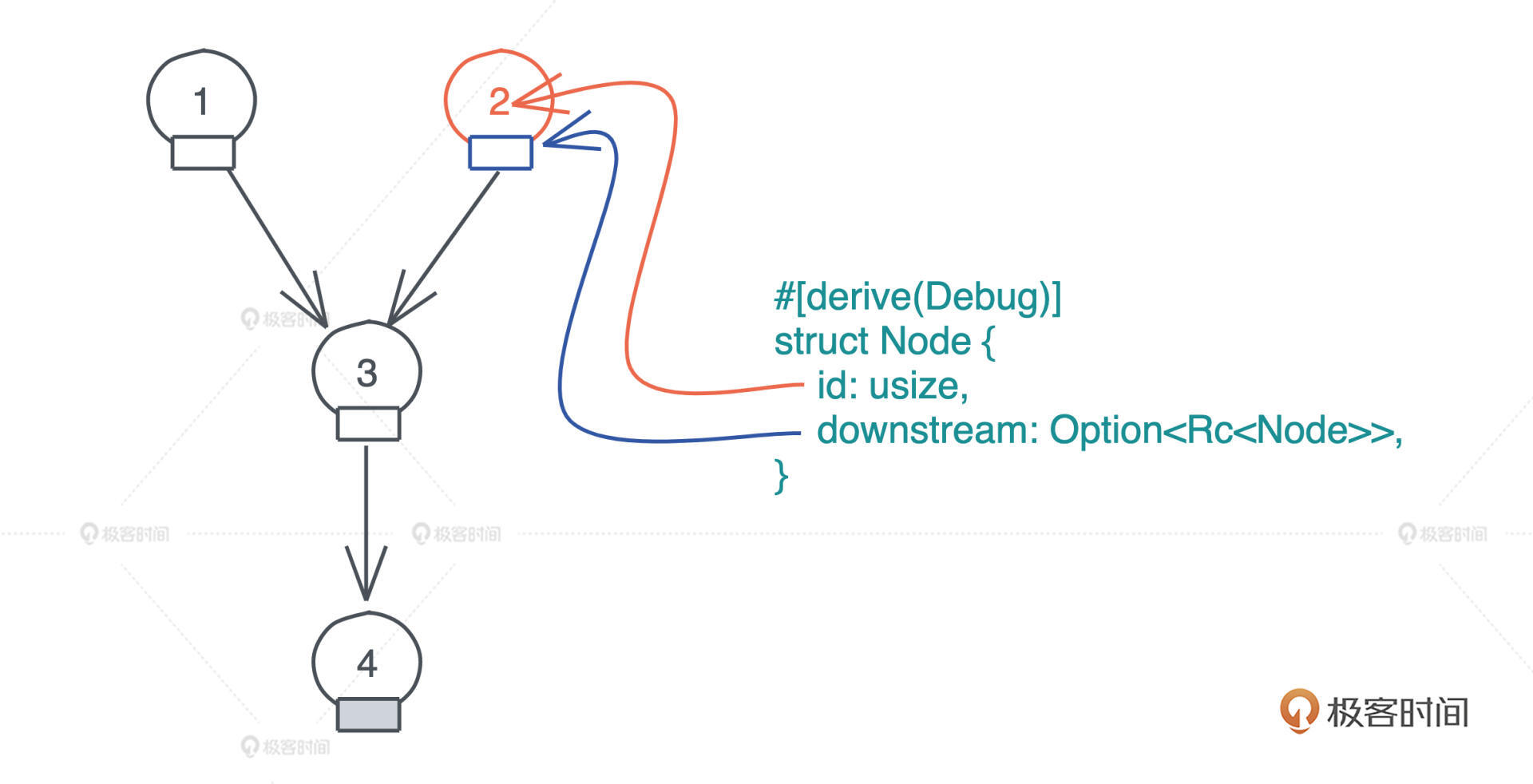
要建立这样一个 DAG,我们需要为 Node 提供以下方法:
new():建立一个新的Node.update_downstream():设置Node的downstream.get_downstream():clone一份Node里的downstream.
于是就有了
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
downstream: Option<Rc<Node>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
downstream: None,
}
}
pub fn update_downstream(&mut self, downstream: Rc<Node>) {
self.downstream = Some(downstream);
}
pub fn get_downstream(&self) -> Option<Rc<Node>> {
self.downstream.as_ref().map(|v| v.clone())
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
let node4 = Node::new(4);
node3.update_downstream(Rc::new(node4));
node1.update_downstream(Rc::new(node3));
node2.update_downstream(node1.get_downstream().unwrap());
println!("node1: {:?}, node2: {:?}", node1, node2);
}
Q:
self.downstream.as_ref().map(|v| v.clone())为什么不是 as_mut 呢?v.clone 不是会 mutate 引用计数吗? A:as_ref()返回的是Option<&T>,而as_mut()返回的是Option<&mut T>,所以as_mut()会改变self的值,而as_ref()不会 (Ps:as_ref()和as_mut()都是Option的方法)
RefCell
在运行上述代码时,也许会疑惑:整个 DAG 在创建完成后还能修改么?
按最简单的写法,我们可以在上面的代码 1 的 main() 函数后,加入这段代码,来修改 Node3 使其指向一个新的节点 Node5:
let node5 = Node::new(5);
let node3 = node1.get_downstream().unwrap();
node3.update_downstream(Rc::new(node5));
println!("node1: {:?}, node2: {:?}", node1, node2);
然而,它无法编译通过,编译器会告诉你“node3 cannot borrow as mutable”.这是因为 Rc 是一个只读的引用计数器,你无法拿到 Rc 结构内部数据的可变引用,来修改这个数据.这可怎么办?
这里,我们需要使用 RefCell.
和 Rc 类似,RefCell 也绕过了 Rust 编译器的静态检查,允许我们在运行时,对某个只读数据进行可变借用.这就涉及 Rust 另一个比较独特且有点难懂的概念:内部可变性(interior mutability)
内部可变性(interior mutability)
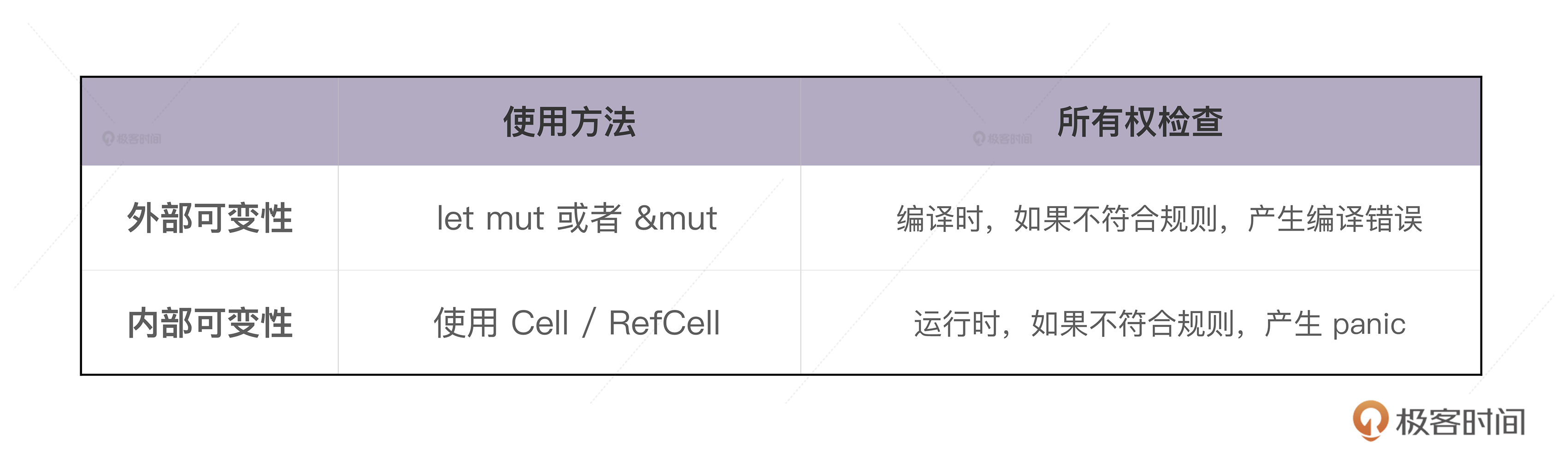
有内部可变性,自然能联想到外部可变性,所以我们先看这个更简单的定义,对比着学习
当我们用 let mut 显式地声明一个可变的值,或者,用 &mut 声明一个可变引用时,编译器可以在编译时进行严格地检查,保证只有可变的值或者可变的引用,才能修改值内部的数据,这被称作外部可变性(exterior mutability),外部可变性通过 mut 关键字声明
然而,这样不够灵活,有时候我们希望能够绕开这个编译时的检查,对并未声明成 mut 的值或者引用,也想进行修改.也就是说,在编译器的眼里,值是只读的,但是在运行时,这个值可以得到可变借用,从而修改内部的数据,这就是 RefCell 的用武之地,也就是内部可变性(interior mutability)
一个 🌰
use std::cell::RefCell;
fn main() {
let data = RefCell::new(1);
{
// 获得 RefCell 内部数据的可变借用
let mut v = data.borrow_mut();
*v += 1;
}
println!("data: {:?}", data.borrow());
}
在这个例子里,data 是一个 RefCell,其初始值为 1.可以看到,我们并未将 data 声明为可变变量.之后我们可以通过使用 RefCell 的 borrow_mut() 方法,来获得一个可变的内部引用,然后对它做加 1 的操作.最后,我们可以通过 RefCell 的 borrow() 方法,获得一个不可变的内部引用,因为加了 1,此时它的值为 2
你也许奇怪,这里为什么要把获取和操作可变借用的两句代码,用花括号分装到一个作用域下?
这是因为,RefCell 的 borrow_mut() 方法,会返回一个 RefMut 结构,它实现了 Drop trait,当 RefMut 结构离开作用域时,会自动调用 Drop trait 的 drop() 方法,这个方法会检查 RefMut 结构的 count 字段,如果它不为 0,说明还有其他的 RefMut 结构在使用 RefCell 的内部数据,所以会 panic
或者说根据所有权规则,在同一个作用域下,我们不能同时有活跃的可变借用和不可变借用.通过这对花括号,我们明确地缩小了可变借用的生命周期,不至于和后续的不可变借用冲突
这里再想一步,如果没有这对花括号,这段代码是无法编译通过?还是运行时会出错?
// 答案是运行时 panic
use std::cell::RefCell;
fn main() {
let data = RefCell::new(1);
let mut v = data.borrow_mut();
*v += 1;
println!("data: {:?}", data.borrow());
}
如果你运行,编译没有任何问题,但在运行到第 9 行时,会得到:thread 'main' panicked at 'already mutably borrowed: BorrowError' 这样的错误.可以看到,所有权的借用规则在此依旧有效,只不过它在运行时检测
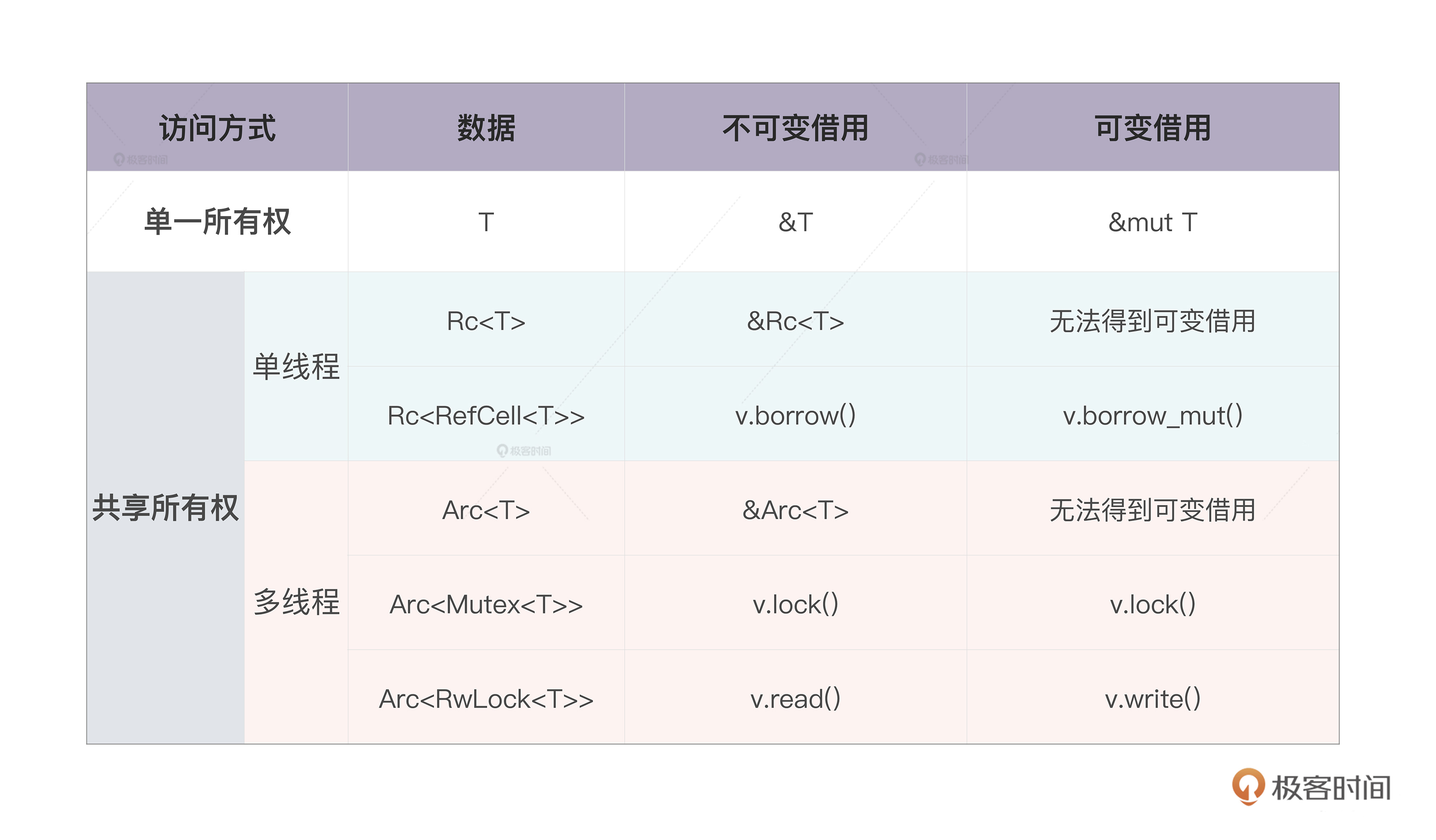
这就是外部可变性和内部可变性的重要区别,我们用下表来总结一下:
实现可修改 DAG
看看如何使用 RefCell 和 Rc 来让之前的 DAG 变得可修改
首先数据结构的 downstream 需要 Rc 内部嵌套一个 RefCell,这样,就可以利用 RefCell 的内部可变性,来获得数据的可变借用了,同时 Rc 还允许值有多个所有者
完整代码如下
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
// 使用 Rc<RefCell<T>> 让节点可以被修改
downstream: Option<Rc<RefCell<Node>>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
downstream: None,
}
}
pub fn update_downstream(&mut self, downstream: Rc<RefCell<Node>>) {
self.downstream = Some(downstream);
}
pub fn get_downstream(&self) -> Option<Rc<RefCell<Node>>> {
self.downstream.as_ref().map(|v| v.clone())
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
let node4 = Node::new(4);
node3.update_downstream(Rc::new(RefCell::new(node4)));
node1.update_downstream(Rc::new(RefCell::new(node3)));
node2.update_downstream(node1.get_downstream().unwrap());
println!("node1: {:?}, node2: {:?}", node1, node2);
let node5 = Node::new(5);
let node3 = node1.get_downstream().unwrap();
// 获得可变引用,来修改 downstream
node3.borrow_mut().downstream = Some(Rc::new(RefCell::new(node5)));
println!("node1: {:?}, node2: {:?}", node1, node2);
}
Arc 和 Mutex/RwLock
Q: 我们用
Rc和RefCell解决了DAG的问题,那么,多个线程访问同一块内存的问题,是否也可以使用Rc来处理呢? A: 不可以,因为Rc是一个只读的引用计数器,它不是线程安全的,所以不能用于多线程环境 (Ps:Rc实现了Send trait,但是没有实现Sync trait,所以不能用于多线程环境)
因此,我们需要另一个引用计数的智能指针:Arc,它实现了线程安全的引用计数器.Arc 的全称是 Atomic reference counter,它是一个原子引用计数器,可以安全地在多个线程中使用
Arc 内部的引用计数使用了 Atomic Usize,而非普通的 usize.从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全.如果对原子类型感兴趣,可以看 std::sync::atomic 的文档.
Rust 实现两套不同的引用计数数据结构,完全是为了性能考虑,从这里我们也可以感受到 Rust 对性能的极致渴求.如果不用跨线程访问,可以用效率非常高的 Rc;如果要跨线程访问,那么必须用 Arc
同样的,RefCell 也不是线程安全的,如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock 来解决这个问题
Mutex 是互斥量,获得互斥量的线程对数据独占访问,RwLock 是读写锁,获得写锁的线程对数据独占访问,但当没有写锁的时候,允许有多个读锁.读写锁的规则和 Rust 的借用规则非常类似,我们可以类比着学
Mutex 和 RwLock 都用在多线程环境下,对共享数据访问的保护上.刚才中我们构建的 DAG 如果要用在多线程环境下,需要把 Rc<RefCell<T>> 替换为 Arc<Mutex<T>> 或者 Arc<RwLock<T>>
练习
// 让这段代码运行
fn main() {
let arr = vec![1];
std::thread::spawn(|| {
println!("{:?}", arr);
});
}
修改后:
use std::sync::{Arc, Mutex};
fn main() {
// 将共享数据包装在 Arc<Mutex<T>> 中:创建一个 Arc<Mutex<T>> 实例来包装需要共享的数据.这里我们使用 arr 变量作为需要共享的数据
let arr = Arc::new(Mutex::new(vec![1]));
// 在新线程中访问共享数据:创建一个新的线程,并在闭包中移动 arr 的所有权.在闭包内部,使用 arr.lock().unwrap()
// 获取互斥锁并访问共享数据.在这个例子中,我们简单地打印出共享数据的内容.
std::thread::spawn({
let arr = Arc::clone(&arr);
// 在 move 闭包中,我们首先对 arr 进行了克隆(使用 Arc::clone() 方法),以便在新线程中拥有 arr 的所有权.然后,我
// 们在闭包内部使用 arr.lock().unwrap() 来获取互斥锁并访问共享数据.这样可以确保同一时间只有一个线程可以访问共享数据
move || {
let data = arr.lock().unwrap();
println!("{:?}", *data);
}
});
// 添加延迟以保证新线程有足够的时间来执行:为了确保新线程有足够的时间来执行打印语句,我们在主线程中添加了一个短暂的延迟
std::thread::sleep(std::time::Duration::from_millis(100));
}
写一段代码,在 main() 函数里生成一个字符串,然后通过 std::thread::spawn 创建一个线程,让 main() 函数所在的主线程和新的线程共享这个字符串
以下为实现(和前面大同小异):
use std::sync::{Arc, Mutex};
fn main() {
let str = Arc::new(Mutex::new(String::from("Aimyon")));
std::thread::spawn({
let str = Arc::clone(&str);
move || {
let data = str.lock().unwrap();
println!("{:?}", *data);
}
});
std::thread::sleep(std::time::Duration::from_millis(100));
}
深入思考:Rc 的 clone():传入的参数是 &self ,是个不可变引用,为什么会增加引用计数呢?(或者说为什么这里对 self 的不可变引用可以改变 self 的内部数据呢?)
A: 因为
Rc实现了Copy trait,所以在进行位拷贝时,会在堆上创建一份新的引用计数,而不是 move
fn clone(&self) -> Rc<T> {
// 增加引用计数
self.inner().inc_strong();
// 通过 self.ptr 生成一个新的 Rc 结构
Self::from_inner(self.ptr)
}
尽管参数是 &self,也就是不可变引用,但是 self.inner().inc_strong() 这一行代码可以成功地修改 self 的内部数据的原因是,inc_strong() 方法的实现可能使用了内部可变性(UnsafeCell).
Rc<T> 类型内部使用了一个包装类型 RcBox<T>,该类型包含了计数器(用于引用计数)以及被共享的数据.而 inc_strong() 方法用于增加计数器的值.
在这个具体的方法实现中,self.inner() 可能返回了一个内部类型 RcBox<T> 的可变引用,并在该可变引用上调用了 inc_strong() 方法.这里使用了内部可变性的概念,在运行时允许通过不可变引用修改数据,但是这种修改是受到限制的,Rust 会确保在同时存在多个引用时,不会发生数据竞争.
总结
如果想绕过“一个值只有一个所有者”的限制,我们可以使用 Rc / Arc 这样带引用计数的智能指针.其中,Rc 效率很高,但只能使用在单线程环境下;Arc 使用了原子结构,效率略低,但可以安全使用在多线程环境下.然而,Rc / Arc 是不可变的,如果想要修改内部的数据,需要引入内部可变性,在单线程环境下,可以在 Rc 内部使用 RefCell;在多线程环境下,可以使用 Arc 嵌套 Mutex 或者 RwLock 的方法
内部可变性:除了 RefCell 之外,Rust 还提供了 Cell.对 RefCell 和 Cell 进一步了解,可以看 Rust 标准库里 cell 的文档