- Published on
Rust入门笔记(十一)
- Authors

- Name
- Et cetera
Lifetime
Value's lifetime
- 如果一个值的生命周期贯穿
整个进程的生命周期,那么我们就称这种生命周期为静态生命周期. - 如果一个值是在
某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么则为动态生命周期.
当值拥有静态生命周期,其引用&也具有静态生命周期.我们在表述这种引用的时候,可以用 'static 来表示.比如: &'static str 代表这是一个具有静态生命周期的字符串引用.一般来说,全局变量、静态变量、字符串字面量(string literal)等,都拥有静态生命周期.我们上文中提到的堆内存,如果使用了 Box::leak 后,也具有静态生命周期
当这个值的作用域结束时,值的生命周期也随之结束.对于动态生命周期,我们约定用 'a 、'b 或者 'hello 这样的小写字符或者字符串来表述. ' 后面具体是什么名字不重要,它代表某一段动态的生命周期,其中, &'a str 和 &'b str 表示这两个字符串引用的生命周期可能不一致
结合下图简单总结:
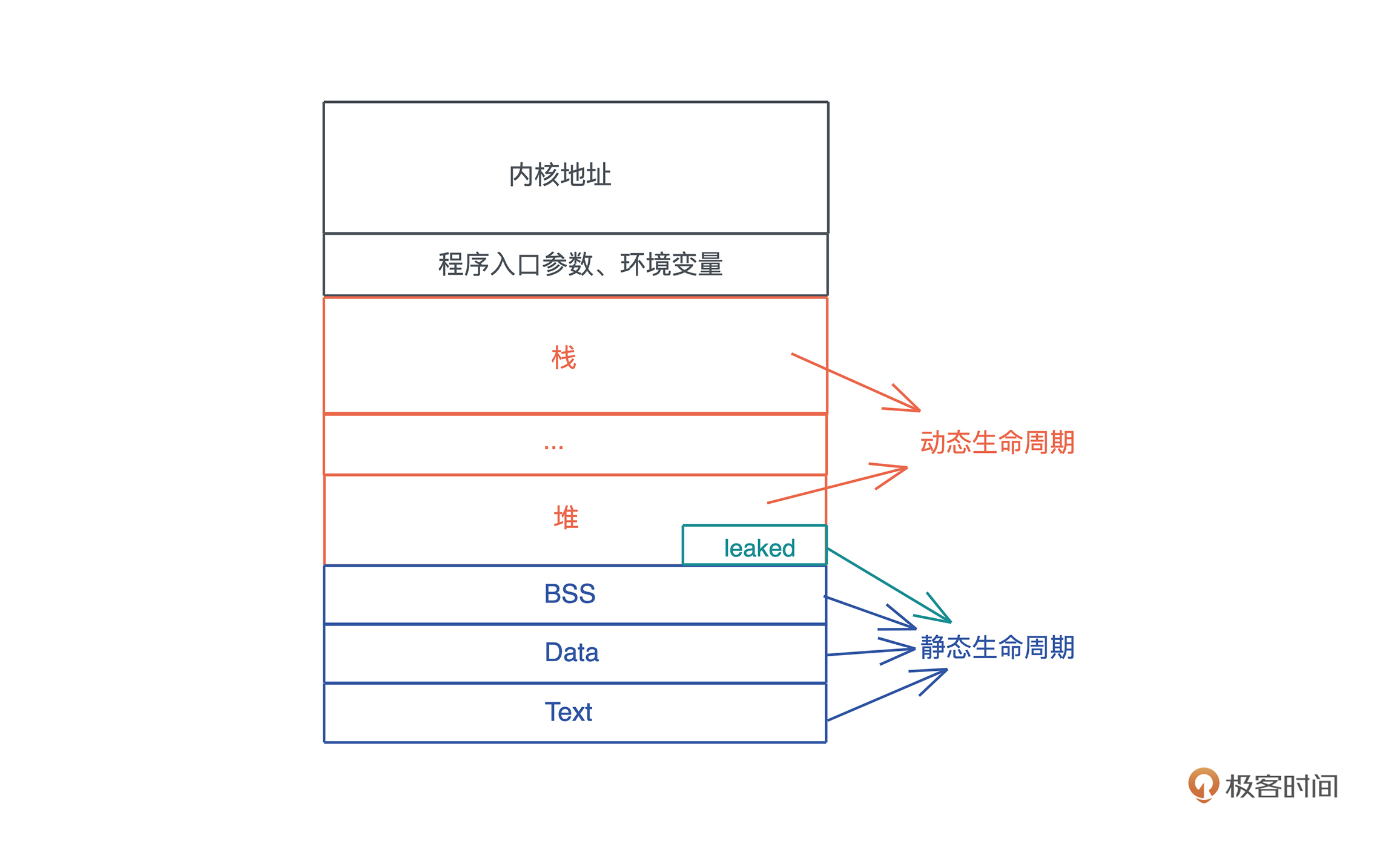
- 分配在堆和栈上的内存有其各自的作用域,它们的生命周期是动态的.
- 全局变量、静态变量、字符串字面量、代码等内容,在编译时,会被编译到可执行文件中的
BSS/Data/RoData/Text段,然后在加载时,装入内存.因而,它们的生命周期和进程的生命周期一致,所以是静态的. - 所以,
函数指针的生命周期也是静态的,因为函数在Text段中,只要进程活着,其内存一直存在.
编译器如何识别生命周期
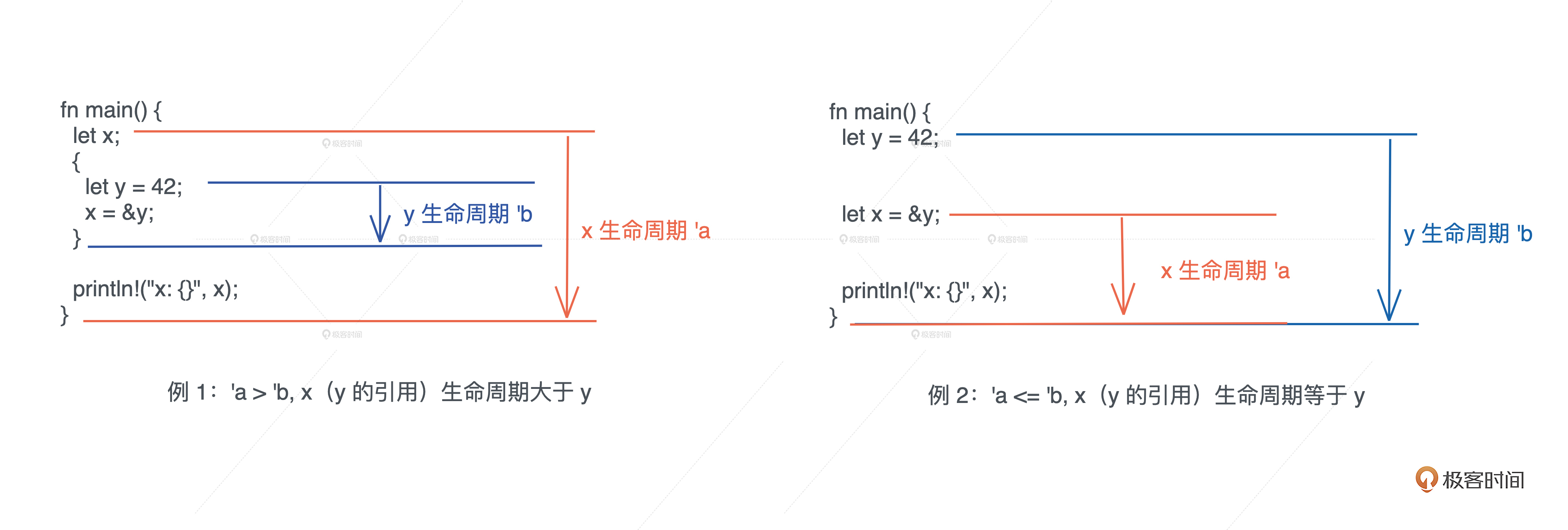
左图的例 1 ,x 引用了在内层作用域中创建出来的变量 y.由于,变量从开始定义到其作用域结束的这段时间,是它的生命周期,所以 x 的生命周期 'a 大于 y 的生命周期 'b,当 x 引用 y 时,编译器报错.
// 列 1 代码
fn main() {
let x;
{
let y = 42;
x = &y;
}
println! ("x:{}", x);
}
右图例 2 中,y 和 x 处在同一个作用域下, x 引用了 y,我们可以看到 x 的生命周期 'a 和 y 的生命周期 'b 几乎同时结束,或者说 'a 小于等于 'b,所以,x 引用 y 是可行的.
// 列 2 代码
fn main() {
let y = 42;
let x = &y;
println! ("x:{}", x);
}
再看个更复杂的例子,main() 函数里创建了两个 String,然后将其传入 max() 函数比较大小.max() 函数接受两个字符串引用,返回其中较大的那个字符串的引用
fn main() {
let s1 = String::from("Lindsey");
let s2 = String::from("Rosie");
let result = max(&s1, &s2);
println!("bigger one: {}", result);
}
fn max(s1: &str, s2: &str) -> &str {
if s1 > s2 {
s1
} else {
s2
}
}
但是这段代码是无法编译通过的,它会报错 “missing lifetime specifier” ,也就是说,编译器在编译 max() 函数时,无法判断 s1、s2 和返回值的生命周期 'a 到底是多长,因为它们都是动态的,所以,编译器无法判断它们的生命周期是否一致,也就无法判断 s1、s2 和返回值的生命周期 'a 是否一致,所以,编译器报错
不过站在我们开发者的角度,这个代码理解起来非常直观,在 main() 函数里 s1 和 s2 两个值生命周期一致,它们的引用传给 max() 函数之后,无论谁的被返回,生命周期都不会超过 s1 或 s2.所以这应该是一段正确的代码啊?
在刚才的示例代码中,我们创建一个新的函数 get_max(),它接受一个字符串引用,然后和 “Cynthia” 这个字符串字面量比较大小.之前我们提到,字符串字面量的生命周期是静态的,而 s1 是动态的,它们的生命周期显然不一致
fn main() {
let s1 = String::from("Lindsey");
let s2 = String::from("Rosie");
let result = max(&s1, &s2);
println!("bigger one: {}", result);
let result = get_max(&s1);
println!("bigger one: {}", result);
}
fn get_max(s1: &str) -> &str {
max(s1, "Cynthia")
}
fn max(s1: &str, s2: &str) -> &str {
if s1 > s2 {
s1
} else {
s2
}
}
当出现了多个参数,它们的生命周期可能不一致时,返回值的生命周期就不好确定了.编译器在编译某个函数时,并不知道这个函数将来有谁调用、怎么调用,所以,函数本身携带的信息,就是编译器在编译时使用的全部信息.
根据这一点,我们再看示例代码,在编译 max() 函数时,参数 s1 和 s2 的生命周期是什么关系、返回值和参数的生命周期又有什么关系,编译器是无法确定的.此时,就需要我们在函数签名中提供生命周期的信息,也就是生命周期标注(lifetime specifier).
在生命周期标注时,使用的参数叫生命周期参数(lifetime parameter).通过生命周期标注,我们告诉编译器这些引用间生命周期的约束.
生命周期参数的描述方式和泛型参数一致,不过只使用小写字母.这里,两个入参 s1、 s2,以及返回值都用 'a 来约束.生命周期参数,描述的是参数和参数之间、参数和返回值之间的关系,并不改变原有的生命周期.
在我们添加了生命周期参数后,s1 和 s2 的生命周期只要大于等于(outlive) 'a,就符合参数的约束,而返回值的生命周期同理,也需要大于等于 'a .
而运行前面两段代码时,编译器(甚至 IDE)已经提示需要添加生命周期标注,所以,我们只需要按照提示添加即可
fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1 > s2 {
s1
} else {
s2
}
}
当 main() 函数调用 max() 函数时,s1 和 s2 有相同的生命周期 'a ,所以它满足 (s1: &'a str, s2: &'a str) 的约束.当 get_max() 函数调用 max() 时,“Cynthia” 是静态生命周期,它大于 s1 的生命周期'a ,所以它也可以满足 max()的约束需求.
什么时候对引用进行标注(为什么我之前写的代码,很多函数的参数或者返回值都使用了引用,编译器却没有提示我要额外标注生命周期呢?)
这是因为编译器希望尽可能减轻开发者的负担,其实所有使用了引用的函数,都需要生命周期的标注,只不过编译器会自动做这件事,省却了开发者的麻烦.
而编译器做的这件事就是,当我们在函数签名中,使用了引用作为参数或者返回值时,编译器会自动为我们添加生命周期标注,这个过程叫生命周期省略(lifetime elision).生命周期省略是编译器的一个特性,它会根据一些规则,自动为我们添加生命周期标注,从而简化代码.
又是一个 🌰:
fn main() {
let s1 = "Hello world";
println!("first word of s1: {}", first(&s1));
}
fn first(s: &str) -> &str {
let trimmed = s.trim();
match trimmed.find(' ') {
None => "",
Some(pos) => &trimmed[..pos],
}
}
上面代码虽然没有做任何生命周期的标注,但编译器会通过一些简单的规则为函数自动添加标注:
- 所有
引用类型的参数都有独立的生命周期'a、'b等. - 如果只有一个引用型输入,它的生命周期会赋给所有输出.
- 如果有多个引用类型的参数,其中一个是
self,那么它的生命周期会赋给所有输出.
规则 3 适用于 trait 或者自定义数据类型,后续再写.例子中的 first() 函数通过规则 1 和 2,可以得到一个带生命周期的版本
fn first<'a>(s: &'a str) -> &'a str {
let trimmed = s.trim();
match trimmed.find(' ') {
None => "",
Some(pos) => &trimmed[..pos],
}
}
可以看到,所有引用都能正常标注,没有冲突.那最开始的 max() 代码为什么编译器无法处理呢?
因为按照规则 1, 我们可以对 max() 函数的参数 s1 和 s2 分别标注'a 和'b ,但是返回值如何标注?是 'a 还是'b 呢?这里的冲突,编译器无能为力.所以,我们需要手动添加标注,告诉编译器返回值的生命周期和参数的生命周期是一致的
实现一个 strtok() 函数
pub fn strtok(s: &mut &str, delimiter: char) -> &str {
if let Some(i) = s.find(delimiter) {
let prefix = &s[..i];
// 由于 delimiter 可以是 utf8,所以我们需要获得其 utf8 长度,
// 直接使用 len 返回的是字节长度,会有问题
let suffix = &s[(i + delimiter.len_utf8())..];
*s = suffix;
prefix
} else { // 如果没找到,返回整个字符串,把原字符串指针 s 指向空串
let prefix = *s;
*s = "";
prefix
}
}
fn main() {
let s = "hello world".to_owned();
let mut s1 = s.as_str();
let hello = strtok(&mut s1, ' ');
println!("hello is: {}, s1: {}, s: {}", hello, s1, s);
}
当我们尝试运行这段代码时,会遇到生命周期相关的编译错误.类似刚才讲的示例代码,是因为按照编译器的规则, &mut &str 添加生命周期后变成 &'b mut &'a str,这将导致返回的 &str 无法选择一个合适的生命周期.
要解决这个问题,我们首先要思考一下:返回值和谁的生命周期有关?是指向字符串引用的可变引用 &mut ,还是字符串引用 &str 本身?
显然是后者.所以,我们可以为 strtok 添加生命周期标注:
pub fn strtok<'b, 'a>(s: &'b mut &'a str, delimiter: char) -> &'a str {...}
因为返回值的生命周期跟字符串引用有关,我们只为这部分的约束添加标注就可以了,剩下的标注交给编译器自动添加,所以代码也可以简化成如下这样,让编译器将其扩展成上面的形式:
pub fn strtok<'a>(s: &mut &'a str, delimiter: char) -> &'a str {...}
最终代码如下:
pub fn strtok<'a>(s: &mut &'a str, delimiter: char) -> &'a str {
if let Some(i) = s.find(delimiter) {
let prefix = &s[..i];
let suffix = &s[(i + delimiter.len_utf8())..];
*s = suffix;
prefix
} else {
let prefix = *s;
*s = "";
prefix
}
}
fn main() {
let s = "hello world".to_owned();
let mut s1 = s.as_str();
let hello = strtok(&mut s1, ' ');
println!("hello is: {}, s1: {}, s: {}", hello, s1, s);
}
结合下图理解上面的最终代码
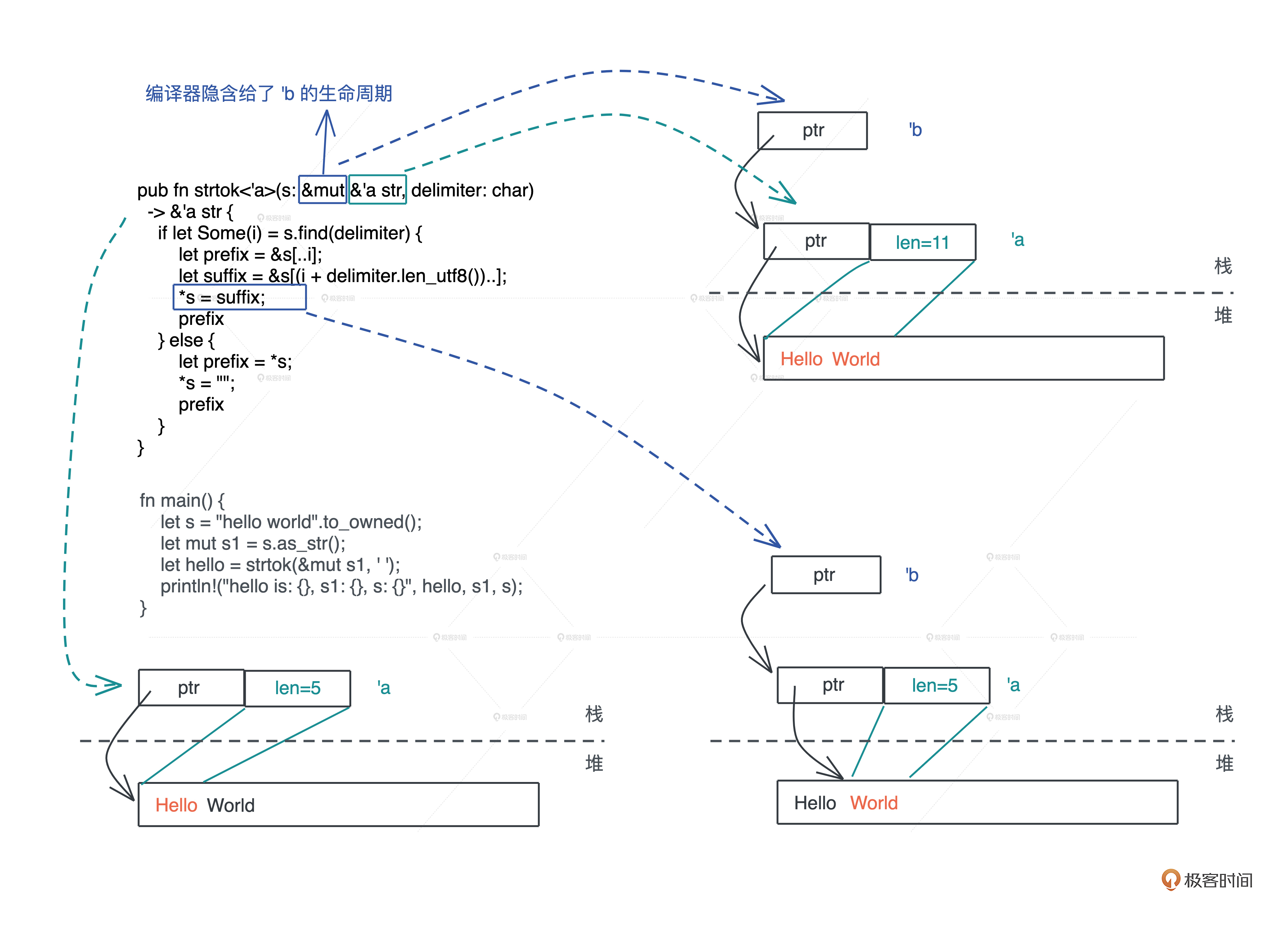
生命周期标注的目的是,在参数和返回值之间建立联系或者约束.调用函数时,传入的参数的生命周期需要大于等于(outlive)标注的生命周期.
当每个函数都添加好生命周期标注后,编译器,就可以从函数调用的上下文中分析出,在传参时,引用的生命周期,是否和函数签名中要求的生命周期匹配.如果不匹配,就违背了“引用的生命周期不能超出值的生命周期”,编译器就会报错.
如果你搞懂了函数的生命周期标注,那么数据结构的生命周期标注也是类似.比如下面的例子,Employee 的 name 和 title 是两个字符串引用,Employee 的生命周期不能大于它们,否则会访问失效的内存,因而我们需要妥善标注:
struct Employee<'a, 'b> {
name: &'a str,
title: &'b str,
age: u8,
}
使用数据结构时,数据结构自身的生命周期,需要小于等于其内部字段的所有引用的生命周期.这样,我们就可以保证,数据结构内部的引用,不会超出数据结构本身的生命周期,从而保证数据结构的安全性.
总结
根据所有权规则,值的生命周期可以确认,它可以一直存活到所有者离开作用域;而引用的生命周期不能超过值的生命周期.在同一个作用域下,这是显而易见的.然而,当发生函数调用时,编译器需要通过函数的签名来确定,参数和返回值之间生命周期的约束.
大多数情况下,编译器可以通过上下文中的规则,自动添加生命周期的约束.如果无法自动添加,则需要开发者手工来添加约束.
一般,我们只需要确定好返回值和哪个参数的生命周期相关就可以了.而对于数据结构,当内部有引用时,我们需要为引用标注生命周期