- Published on
Rust入门笔记(十二)
- Authors

- Name
- Et cetera
值的创建
当我们为数据结构创建一个值,并将其赋给一个变量时,根据值的性质,它有可能被创建在栈上,也有可能被创建在堆上.
理论上,编译时可以确定大小的值都会放在栈上,包括 Rust 提供的原生类型比如字符、数组、元组(tuple)等,以及开发者自定义的固定大小的结构体(struct)、枚举(enum) 等.
如果数据结构的大小无法确定,或者它的大小确定但是在使用时需要更长的生命周期,就最好放在堆上.
struct
Rust 在内存中排布数据时,会根据每个域的对齐(aligment)对数据进行重排,使其内存大小和访问效率最好.比如,一个包含 A、B、C 三个域的 struct,它在内存中的布局可能是 A、C、B:
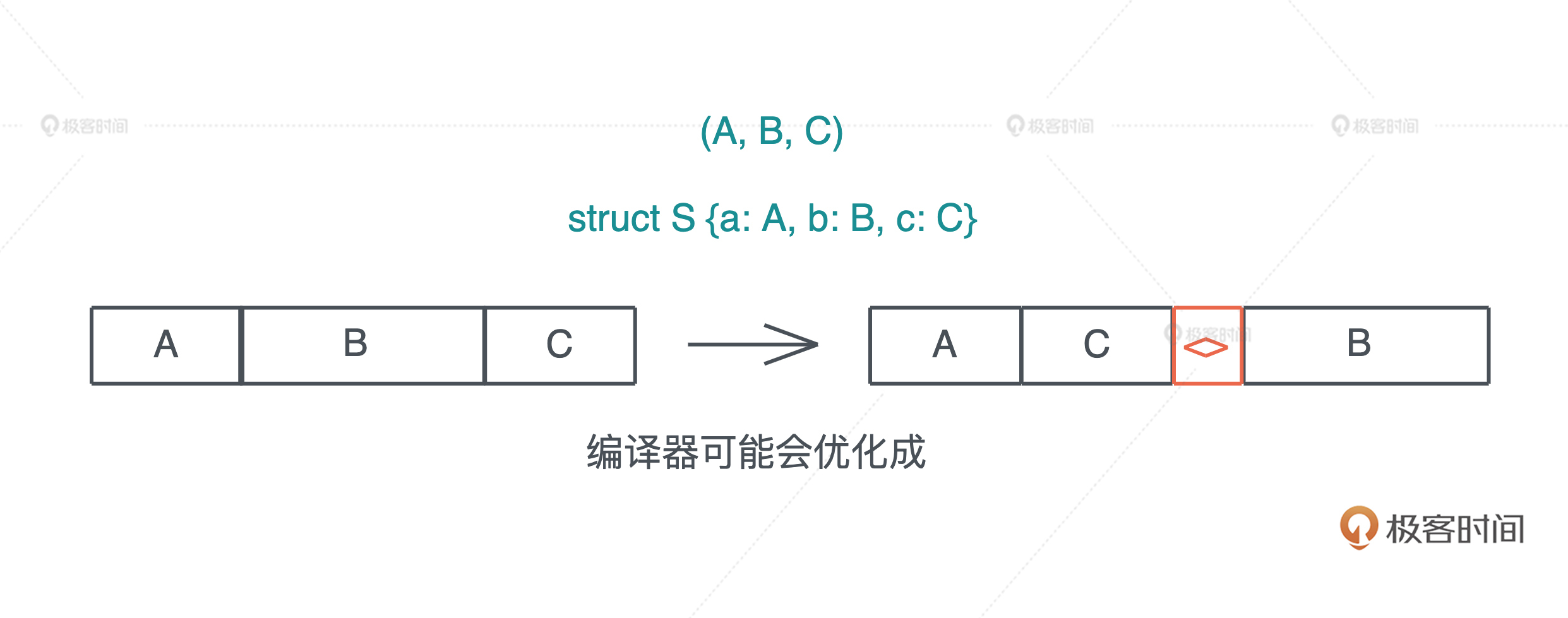
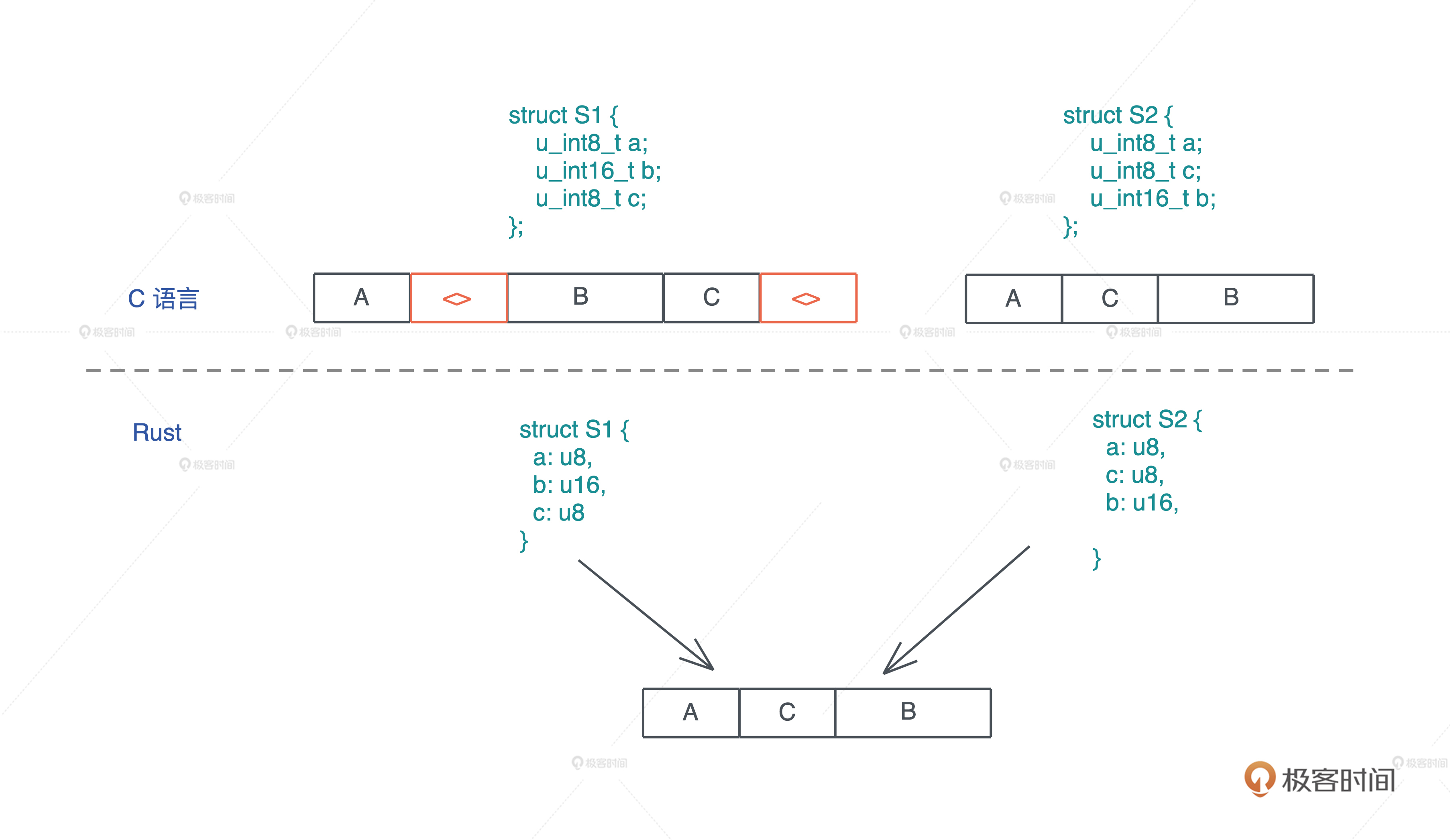
为什么 Rust 编译器会这么做呢?我们先看看 C 语言在内存中表述一个结构体时遇到的问题.来写一段代码,其中两个数据结构 S1 和 S2 都有三个域 a、b、c,其中 a 和 c 是 u8,占用一个字节,b 是 u16,占用两个字节.S1 在定义时顺序是 a、b、c,而 S2 在定义时顺序是 a、c、b:
#include <stdio.h>
struct S1 {
u_int8_t a;
u_int16_t b;
u_int8_t c;
};
struct S2 {
u_int8_t a;
u_int8_t c;
u_int16_t b;
};
void main() {
printf("size of S1: %d, S2: %d", sizeof(struct S1), sizeof(struct S2));
}
正确答案是:6 和 4.
为什么明明只用了 4 个字节,S1 的大小却是 6 呢?这是因为 CPU 在加载不对齐的内存时,性能会急剧下降,所以要避免用户定义不对齐的数据结构时,造成的性能影响.
对于这个问题,C 语言会对结构体会做这样的处理:
- 首先确定每个域的长度和对齐长度,原始类型的对齐长度和类型的长度一致.
- 每个域的
起始位置要和其对齐长度对齐,如果无法对齐,则添加padding直至对齐. - 结构体的对齐大小和其最大域的对齐大小相同,而结构体的长度则四舍五入到其对齐的倍数.
对于 S1,字段 a 是 u8 类型,所以其长度和对齐都是 1,b 是 u16,其长度和对齐是 2.然而因为 a 只占了一个字节,b 的偏移是 1,根据第二条规则,起始位置和 b 的长度无法对齐,所以编译器会添加一个字节的 padding,让 b 的偏移为 2,这样 b 就对齐了.

随后 c 长度和对齐都是 1,不需要 padding.这样算下来,S1 的大小是 5,但根据上面的第三条规则,S1 的对齐是 2,和 5 最接近的“2 的倍数”是 6,所以 S1 最终的长度是 6.其实,这最后一条规则是为了让 S1 放在数组中,可以有效对齐.
所以,如果结构体的定义考虑地不够周全,会为了对齐浪费很多空间.我们看到,保存同样的数据,S1 和 S2 的大小相差了 50%.
使用 C 语言时,定义结构体的最佳实践是,充分考虑每一个域的对齐,合理地排列它们,使其内存使用最高效.这个工作由开发者做会很费劲,尤其是嵌套的结构体,需要仔细地计算才能得到最优解.
而 Rust 编译器替我们自动完成了这个优化,这就是为什么 Rust 会自动重排你定义的结构体,来达到最高效率.我们看同样的代码,在 Rust 下,S1 和 S2 大小都是 4
use std::mem::{align_of, size_of};
struct S1 {
a: u8,
b: u16,
c: u8,
}
struct S2 {
a: u8,
c: u8,
b: u16,
}
fn main() {
println!("sizeof S1: {}, S2: {}", size_of::<S1>(), size_of::<S2>());
println!("alignof S1: {}, S2: {}", align_of::<S1>(), align_of::<S2>());
}
结合下图对比 C 和 rust 的内存布局:
虽然,Rust 编译器默认为开发者优化结构体的排列,但你也可以使用#[repr] 宏,强制让 Rust 编译器不做优化,和 C 的行为一致,这样,Rust 代码可以方便地和 C 代码无缝交互.
enum
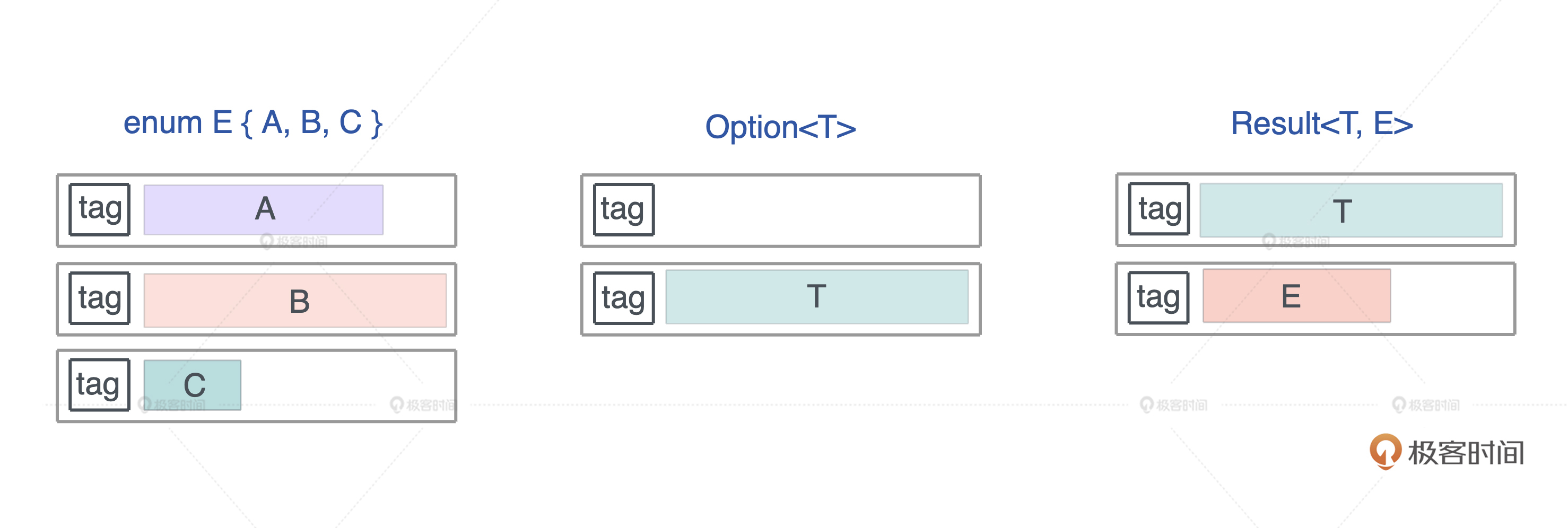
在 Rust 下它是一个标签联合体(tagged union),它的大小是标签的大小,加上最大类型的长度.
定义 enum 数据结构时,有 Option 和 Result 两种设计, Option 是有值 / 无值这种最简单的枚举类型,Result 包括成功返回数据和错误返回数据的枚举类型,后面会详细讲到.
根据刚才说的三条对齐规则,tag 后的内存,会根据其对齐大小进行对齐,所以对于 Option,其长度是 1 + 1 = 2 字节,而 Option,长度是 8 + 8 =16 字节.一般而言,64 位 CPU 下,enum 的最大长度是:最大类型的长度 + 8,因为 64 位 CPU 的最大对齐是 64bit,也就是 8 个字节.
下图展示了 enum、Option 以及 Result 的布局:
Rust 编译器会对 enum 做一些额外的优化,让某些常用结构的内存布局更紧凑.
use std::collections::HashMap;
use std::mem::size_of;
enum E {
A(f64),
B(HashMap<String, String>),
C(Result<Vec<u8>, String>),
}
// 这是一个声明宏,它会打印各种数据结构本身的大小,在 Option 中的大小,以及在 Result 中的大小
macro_rules! show_size {
(header) => {
println!(
"{:<24} {:>4} {} {}",
"Type", "T", "Option<T>", "Result<T, io::Error>"
);
println!("{}", "-".repeat(64));
};
($t:ty) => {
println!(
"{:<24} {:4} {:8} {:12}",
stringify!($t),
size_of::<$t>(),
size_of::<Option<$t>>(),
size_of::<Result<$t, std::io::Error>>(),
)
};
}
fn main() {
show_size!(header);
show_size!(u8);
show_size!(f64);
show_size!(&u8);
show_size!(Box<u8>);
show_size!(&[u8]);
show_size!(String);
show_size!(Vec<u8>);
show_size!(HashMap<String, String>);
show_size!(E);
}
这段代码包含了一个声明宏(declarative macro)show_size,我们先不必管它.运行这段代码时,你会发现,Option 配合带有引用类型的数据结构,比如 &u8、Box、Vec、HashMap ,没有额外占用空间
Type T Option<T> Result<T, io::Error>
----------------------------------------------------------------
u8 1 2 24
f64 8 16 24
&u8 8 8 24
Box<u8> 8 8 24
&[u8] 16 16 24
String 24 24 32
Vec<u8> 24 24 32
HashMap<String, String> 48 48 56
E 56 56 64
对于 Option 结构而言,它的 tag 只有两种情况:0 或 1, tag 为 0 时,表示 None,tag 为 1 时,表示 Some
正常来说,当我们把它和一个引用放在一起时,虽然 tag 只占 1 个 bit,但 64 位 CPU 下,引用结构的对齐是 8,所以它自己加上额外的 padding,会占据 8 个字节,一共 16 字节,这非常浪费内存.怎么办呢?
Rust 是这么处理的,我们知道,引用类型的第一个域是个指针,而指针是不可能等于 0 的,但是我们可以复用这个指针:当其为 0 时,表示 None,否则是 Some,减少了内存占用,这是个非常巧妙的优化,我们可以学习.